The database buffer cache, also called the buffer cache, is the memory area that stores copies of data blocks read from data files.
A buffer is a main memory address in which the buffer manager temporarily caches a currently or recently used data block. All users concurrently connected to a database instance share access to the buffer cache.
It stores copies of data blocks that are read from data files. A buffer is a main memory address in which the buffer manager temporarily caches a currently or recently used data block. All users that are concurrently connected to a database instance share access to the buffer cache. The goals of the buffer cache are to optimize physical I/O, keep frequently accessed blocks in the buffer cache, and manage buffer headers that point to data files in the optional Oracle Persistent Memory File store (PMEM File store).
The first time an Oracle Database client process requires a particular piece of data, it searches for the data in the database buffer cache. If the process finds the data already in the cache (a cache hit), it can read the data directly from memory. If the process cannot find the data in the cache (a cache miss), it copies the data block from a data file on disk into a buffer in the cache before accessing the data. Accessing data through a cache hit is faster than accessing data through a cache miss.
The buffers in the cache are managed by a complex algorithm that uses a combination of least recently used (LRU) lists and touch count. The LRU helps to ensure that the most recently used blocks tend to stay in memory to minimize disk access.
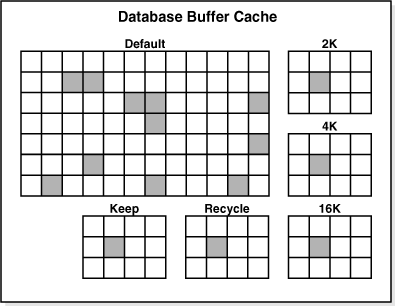
The database buffer cache consists of the following areas:
* The default pool is the location where blocks are normally cached. The default block size is 8 KB. Unless you manually configure separate pools, the default pool is the only buffer pool. The optional configuration of the other pools has no effect on the default pool.
(Optional) The keep pool is for blocks that are expected to be accessed frequently and would have aged out of the default pool because of lack of space. The purpose of the keep buffer pool isto retain specified objects in memory to avoid I/O operations. Tables are assigned to the keep pool. They don't move from the default pool to the keep pool automatically.
(Optional) The recycle pool is for blocks that are used infrequently. A recycle pool prevents objects from consuming unnecessary space in the cache.
(Optional) Non default buffer pools are for tablespaces that use the nonstandard block sizes of 2 KB, 4 KB, 16 KB, and 32 KB. Each non-default block size has its own pool. Oracle Database manages the blocks in these pools in the same way as in the default pool.
(Optional) Database Smart Flash Cache (flash cache) lets you use flash devices to increase the effective size of the buffer cache without adding more main memory. Flash cache can improve database performance by storing the database cache frequently accessed data stored into flash memory instead of reading the data from magnetic disk. When the database requests data, the system first looks in the database buffer cache. If the data is not found, the system then looks in the Database Smart Flash Cache buffer. If it does not find the data there, only then does it lookin disk storage. You must configure a flash cache on either all or none of the instances in an Oracle Real Application Clusters(RAC) environment
The least recently used (LRU) list contains pointers to dirty and non-dirty buffers. The LRU list has a hot end and a cold end. A cold buffer is a buffer that has not been recently used. A hot buffer is frequently accessed and has been recently used. Conceptually, there is only one LRU, but for data concurrency the database actually uses several LRUs.
The checkpoint queue is a list of dirty buffers in the order they were changed based on the redo block address(RBA) order.
(Optional) If you enable Database Smart Flash Cache, the flash buffer area consists of a DEFAULT flash LRU chain and a KEEP flash LRU chain. Without Database Smart Flash Cache, when a process tries to access a block and the block does not exist in the buffer cache, the block is first read from disk into memory(physical read). When the in-memory buffer cache gets full, a buffer is evicted out of the memory based on an LRU mechanism. With Database Smart Flash Cache, when a clean in-memory buffer ages out, the database writer process
(DBWn) writes the content to the flash cache in the background, and the buffer header remains in memory as metadata in either the DEFAULT or KEEP flash LRU list, depending on the value of the FLASH_CACHE object attribute. The KEEP flash LRU list maintains the buffer headers on a separate list to prevent the regular buffer headers from replacing them. This means that the flash buffer headers belonging to an object that is specified as KEEP tend to stay in the flash cache longer. If the FLASH_CACHE object attribute is set to NONE, the system does not retain the corresponding buffers in the flash cache or in memory. When a buffer that was already aged out of memory is accessed again, the system checks the flash cache. If the buffer is found, it reads it back from the flash cache, which takes only a fraction of the time of reading from the disk. The consistency of flash cache buffers across RAC is maintained in the same way as by Oracle RAC Cache Fusion. Because the flash cache is an extended cache and direct path I/O totally bypasses the buffer cache, this feature does not support direct path I/O.
Note that the system does not put dirty buffers in flash cache because it may have to read buffers into memory to checkpoint them because writing to flash cache does not count for checkpoint.
(Optional) If you enable the PMEM File store and migrate data files into the PMEM File store, then database files are mapped for direct read-only access. Queries can bypass the traditional buffer cache mechanism, avoiding unnecessary I/O.
In this case, buffer headers must store metadata corresponding to the PMEM blocks. The database can still use the traditional (DRAM) buffer cache for modifications, read consistency, and faster access for "hot" data blocks.
Purpose of the Database Buffer Cache:
Oracle Database uses the buffer cache to achieve multiple goals.
Buffer States
The database uses internal algorithms to manage buffers in the cache.
Buffer Modes
When a client requests data, Oracle Database retrieves buffers from the database buffer cache in either current mode or consistent mode.
Buffer I/O
A logical I/O, also known as a buffer I/O, refers to reads and writes of buffers in the buffer cache.
Buffer Pools
A buffer pool is a collection of buffers.
Buffers and Full Table Scans
The database uses a complicated algorithm to manage table scans. By default, when buffers must be read from disk, the database inserts the buffers into the middle of the LRU list. In this way, hot blocks can remain in the cache so that they do not need to be read from disk again.
DRAM and PMEM Buffers
Standard (DRAM) database buffers differ from PMEM buffers, but they share characteristics.
Buffer States
The database uses internal algorithms to manage buffers in the cache. A buffer can be in any of the following mutually exclusive states:
Unused
The buffer is available for use because it has never been used or is currently unused. This type of buffer is the easiest for the database to use.
Clean
This buffer was used earlier and now contains a read-consistent version of a block as of a point in time. The block contains data but is "clean" so it does not need to be checkpointed. The database can pin the block and reuse it.
Dirty
The buffer contain modified data that has not yet been written to disk. The database must checkpoint the block before reusing it.
Every buffer has an access mode: pinned or free (unpinned). A buffer is "pinned" in the cache so that it does not age out of memory while a user session accesses it. Multiple sessions cannot modify a pinned buffer at the same time.
Buffer I/O
A logical I/O, also known as a buffer I/O, refers to reads and writes of buffers in the buffer cache.
When a requested buffer is not found in memory, the database performs a physical I/O to copy the buffer from either the flash cache or disk into memory. The database then performs a logical I/O to read the cached buffer.
Buffer Replacement Algorithms
To make buffer access efficient, the database must decide which buffers to cache in memory, and which to access from disk.
Buffer Writes
The database writer (DBW) process periodically writes cold, dirty buffers to disk.
Buffer Reads
When the number of unused buffers is low, the database must remove buffers from the buffer cache.
Buffer Touch Counts
The database measures the frequency of access of buffers on the LRU list using a touch count. This mechanism enables the database to increment a counter when a buffer is pinned instead of constantly shuffling buffers on the LRU list.
The database uses the following algorithms:
LRU-based, block-level replacement algorithm
This sophisticated algorithm, which is the default, uses a least recently used (LRU) list that contains pointers to dirty and non-dirty buffers. The LRU list has a hot end and cold end. A cold buffer is a buffer that has not been recently used. A hot buffer is frequently accessed and has been recently used. Conceptually, there is only one LRU, but for data concurrency the database actually uses several LRUs.
When a table does not fit in memory, the database decides which buffers to cache based on access patterns. For example, if only 95% of a popular table fits in memory, then the database may choose to leave 5% of the blocks on disk rather than cyclically reading blocks into memory and writing blocks to disk—a phenomenon known as thrashing. When caching multiple large objects, the database considers more popular tables hotter and less popular tables cooler, which influences which blocks are cached.
The DB_BIG_TABLE_CACHE_PERCENT_TARGET initialization parameter sets the percentage of the buffer cache that uses this algorithm.
Buffer Writes
The database writer (DBW) process periodically writes cold, dirty buffers to disk.
DBW writes buffers in the following circumstances:
1. A server process cannot find clean buffers for reading new blocks into the database buffer cache.
2. As buffers are dirtied, the number of free buffers decreases. If the number drops below an internal threshold, and if clean buffers are required, then server processes signal DBW to write.
3. The database uses the LRU to determine which dirty buffers to write. When dirty buffers reach the cold end of the LRU, the database moves them off the LRU to a write queue. DBW writes buffers in the queue to disk, using multiblock writes if possible. This mechanism prevents the end of the LRU from becoming clogged with dirty buffers and allows clean buffers to be found for reuse.
4. The database must advance the checkpoint, which is the position in the redo thread from which instance recovery must begin.
5. Tablespaces are changed to read-only status or taken offline.
Buffer Reads
When the number of unused buffers is low, the database must remove buffers from the buffer cache.
The algorithm depends on whether the flash cache is enabled:
Flash cache disabled
The database re-uses each clean buffer as needed, overwriting it. If the overwritten buffer is needed later, then the database must read it from magnetic disk.
Flash cache enabled
DBW can write the body of a clean buffer to the flash cache, enabling reuse of its in-memory buffer. The database keeps the buffer header in an LRU list in main memory to track the state and location of the buffer body in the flash cache. If this buffer is needed later, then the database can read it from the flash cache instead of from magnetic disk.
When a client process requests a buffer, the server process searches the buffer cache for the buffer. A cache hit occurs if the database finds the buffer in memory. The search order is as follows:
1. The server process searches for the whole buffer in the buffer cache. If the process finds the whole buffer, then the database performs a logical read of this buffer.
2. The server process searches for the buffer header in the flash cache LRU list. If the process finds the buffer header, then the database performs an optimized physical read of the buffer body from the flash cache into the in-memory cache.
3. If the process does not find the buffer in memory (a cache miss), then the server process performs the following steps:
a) Copies the block from a data file on disk into memory (a physical read)
b) Performs a logical read of the buffer that was read into memory
In general, accessing data through a cache hit is faster than through a cache miss.
The buffer cache hit ratio measures how often the database found a requested block in the buffer cache without needing to read it from disk.
The database can perform physical reads from either a data file or a temp file. Reads from a data file are followed by logical I/Os. Reads from a temp file occur when insufficient memory forces the database write data to a temporary table and read it back later. These physical reads bypass the buffer cache and do not incur a logical I/O.
Buffer Touch Counts
The database measures the frequency of access of buffers on the LRU list using a touch count. This mechanism enables the database to increment a counter when a buffer is pinned instead of constantly shuffling buffers on the LRU list.
When a buffer is pinned, the database determines when its touch count was last incremented. If the count was incremented over three seconds ago, then the count is incremented; otherwise, the count stays the same. The three-second rule prevents a burst of pins on a buffer counting as many touches. For example, a session may insert several rows in a data block, but the database considers these inserts as one touch.
If a buffer is on the cold end of the LRU, but its touch count is high, then the buffer moves to the hot end. If the touch count is low, then the buffer ages out of the cache.
Keep pool
This pool is intended for blocks that were accessed frequently, but which aged out of the default pool because of lack of space. The purpose of the keep buffer pool is to retain objects in memory, thus avoiding I/O operations.
A database has a standard block size. You can create a tablespace with a block size that differs from the standard size. Each nondefault block size has its own pool. Oracle Database manages the blocks in these pools in the same way as in the default pool.
The following figure shows the structure of the buffer cache when multiple pools are used. The cache contains default, keep, and recycle pools. The default block size is 8 KB. The cache contains separate pools for tablespaces that use the nonstandard block sizes of 2 KB, 4 KB, and 16 KB.
Buffers and Full Table Scans
The database uses a complicated algorithm to manage table scans. By default, when buffers must be read from disk, the database inserts the buffers into the middle of the LRU list. In this way, hot blocks can remain in the cache so that they do not need to be read from disk again.
A problem is posed by a full table scan, which sequentially reads all rows under the table high water mark (HWM). Suppose that the total size of the blocks in a table segment is greater than the size of the buffer cache. A full scan of this table could clean out the buffer cache, preventing the database from maintaining a cache of frequently accessed blocks.
Default Mode for Full Table Scans
By default, the database takes a conservative approach to full table scans, loading a small table into memory only when the table size is a small percentage of the buffer cache.
To determine whether medium sized tables should be cached, the database uses an algorithm that incorporates the interval between the last table scan, the aging timestamp of the buffer cache, and the space remaining in the buffer cache.
For very large tables, the database typically uses a direct path read, which loads blocks directly into the PGA and bypasses the SGA altogether, to avoid populating the buffer cache. For medium size tables, the database may use a direct read or a cache read. If it decides to use a cache read, then the database places the blocks at the end of the LRU list to prevent the scan from effectively cleaning out the buffer cache.
Starting in Oracle Database 12c Release 1 (12.1.0.2), the buffer cache of a database instance automatically performs an internal calculation to determine whether memory is sufficient for the database to be fully cached in the instance SGA, and if caching tables on access would be beneficial for performance. If the whole database can fully fit in memory, and if various other internal criteria are met, then Oracle Database treats all tables in the database as small tables, and considers them eligible for caching. However, the database does not cache LOBs marked with the NOCACHE attribute.
Parallel Query Execution
When performing a full table scan, the database can sometimes improve response time by using multiple parallel execution servers.
In some cases, as when the database has a large amount of memory, the database can cache parallel query data in the system global area (SGA) instead of using direct path reads into the program global area (PGA). Typically, parallel queries occur in low-concurrency data warehouses because of the potential resource usage.
DRAM and PMEM Buffers
Standard (DRAM) database buffers differ from PMEM buffers, but they share characteristics.
When Oracle Persistent Memory Filestore (PMEM Filestore) is configured, every data block is directly mapped to the buffer cache in DRAM. Unlike DRAM buffers, PMEM buffers do not copy the contents of data blocks. Rather, PMEM buffer headers point to data blocks stored in PMEM Filestore. For most reads, the database only caches the block metadata, not the contents. PMEM buffers use a special type of granule whose structure is different from standard buffer cache granules.
PMEM buffers can be in any of the following states:
Current
This is the current version of a PMEM buffer. It can be directly accessed from the file store.
Oracle Database keeps the PMEM current version separate from the standard DRAM buffer current version. This separation helps to reduce code complexity during PMEM block pinning, cleanup, and migrate to DRAM.
Consistent
This is the consistent read version of a PMEM buffer. It is created after the database creates a clone in DRAM. The PMEM buffer can be directly accessed from the file store.
Free
This is a free PMEM buffer. It can be reused by a PMEM block. After instance startup, all PMEM buffers are in a free state.
PMEM has higher latency than DRAM. Oracle Database uses an internal, workload-based algorithm to decide which blocks to migrate from PMEM to DRAM.