
The most crucial structure for recovery is the online redo log, which consists of two or more preallocated files that store changes to the database as they occur. The online redo log records changes to the data files.
Use of the Online Redo Log
The database maintains online redo log files to protect against data loss. Specifically, after an instance failure, the online redo log files enable Oracle Database to recover committed data that it has not yet written to the data files.
Server processes write every transaction synchronously to the redo log buffer, which the LGWR process then writes to the online redo log. Contents of the online redo log include uncommitted transactions, and schema and object management statements.
As the database makes changes to the undo segments, the database also writes these changes to the online redo logs. Consequently, the online redo log always contains the undo data for permanent objects. You can configure the database to store all undo data for temporary objects in a temporary undo segment, which saves space and improves performance, or allow the database to store both permanent and temporary undo data in the online redo log.
How Oracle Database Writes to the Online Redo Log
The online redo log for a database instance is called a redo thread.
In single-instance configurations, only one instance accesses a database, so only one redo thread is present. In an Oracle Real Application Clusters (Oracle RAC) configuration, however, multiple instances concurrently access a database, with each instance having its own redo thread. A separate redo thread for each instance avoids contention for a single set of online redo log files.
An online redo log consists of two or more online redo log files. Oracle Database requires a minimum of two files to guarantee that one file is always available for writing in case the other file is in the process of being cleared or archived.
Online Redo Log Switches
Oracle Database uses only one online redo log file at a time to store records written from the redo log buffer.
The online redo log file to which the log writer process (LGWR) process is actively writing is called the current online redo log file.
A log switch occurs when the database stops writing to one online redo log file and begins writing to another. Normally, a switch occurs when the current online redo log file is full and writing must continue. However, you can configure log switches to occur at regular intervals, regardless of whether the current online redo log file is filled, and force log switches manually.
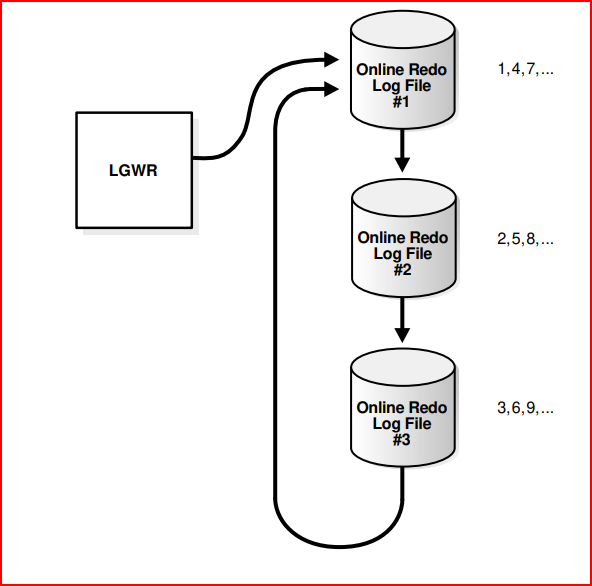
The numbers shows the sequence in which LGWR writes to each online redo log file. The database assigns each file a new log sequence number when a log switches and log writers begins writing to it. When the database reuses an online redo log file, this file receives the next available log sequence number. Filled online redo log files are available for reuse depending on the archiving mode: • If archiving is disabled, which means that the database is in NOARCHIVELOG mode, then a filled online redo log file is available after the changes recorded in it have been checkpointed (written) to disk by database writer (DBW). • If archiving is enabled, which means that the database is in ARCHIVELOG mode, then a filled online redo log file is available to log writer after the changes have been written to the data files and the file has been archived. In some circumstances, log writer may be prevented from reusing an existing online redo log file. An active online redo log file is required for instance recovery, where as an inactive online redo log file is not required for instance recovery. Also, an online redo log file may be in the process of being cleared.
Multiple Copies of Online Redo Log Files
Oracle Database can automatically maintain two or more identical copies of the online redo log in separate locations.
An online redo log group consists of an online redo log file and its redundant copies.
Each identical copy is a member of the online redo log group. Each group is defined by a number, such as group 1, group 2, and so on.
Maintaining multiple members of an online redo log group protects against the loss of the redo log. Ideally, the locations of the members should be on separate disks so that the failure of one disk does not cause the loss of the entire online redo log.
In Figure below, A_LOG1 and B_LOG1 are identical members of group 1, while A_LOG2 and B_LOG2 are identical members of group 2. Each member in a group must be the same size. LGWR writes concurrently to group 1 (members A_LOG1 and B_LOG1), then writes concurrently to group 2 (members A_LOG2 and B_LOG2), then writes to group 1, and so on. LGWR never writes concurrently to members of different groups.
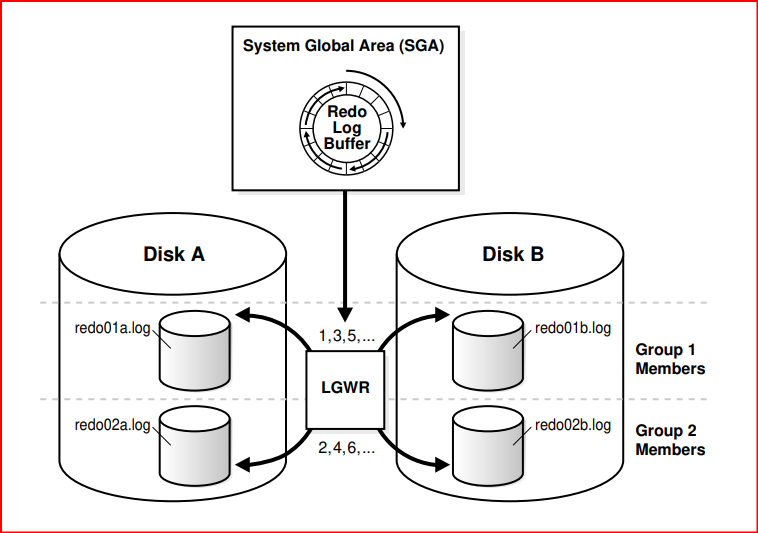
Structure of the Online Redo Log
Online redo log files contain redo records.
A redo record is made up of a group of change vectors, each of which describes a change to a data block. For example, an update to a salary in the employees table generates a redo record that describes changes to the data segment block for the table, the undo segment data block, and the transaction table of the undo segments.
The redo records have all relevant metadata for the change, including the following:
• SCN and time stamp of the change
• Transaction ID of the transaction that generated the change
• SCN and time stamp when the transaction committed (if it committed)
• Type of operation that made the change
• Name and type of the modified data segment
add the new group with 100MB size
SQL> Alter database orcl add logfile group 2 ('/u01/app/oracle/orcl/redo02.log','/u01/app/oracle/orcl/redo02.log') size 100m blocksize 512 reuse;
or,
SQL> alter database add logfile group 1 '/u01/app/oracle/oradata/redo1.log' size 100M;
SQL> alter database add logfile group 2 '/u01/app/oracle/oradata/redo2.log' size 100M;
Check the name of the redolog groups
SQL> select group#,type,member from v$logfile order by group#;
Check the status of Online redo logs
SQL> select group#, (bytes/1024/1024) BYTES_IN_MB, status from v$log;
Perform few log switches
SQL> alter system switch logfile;
It’s always a better to do a checkpoint. So it will make the Active groups to Inactive.
SQL> alter system checkpoint;
SQL> select group#, status from v$log;
GROUP# STATUS
--------- ----------------
1 INACTIVE
2 INACTIVE
3 INACTIVE
Once all the groups which are in smaller size are INACTIVE and Now we can drop
SQL> alter database drop logfile group 1;
SQL> alter database drop logfile group 2;
SQL> alter database drop logfile group 3;
In case you have your database on ASM then
alter database add logfile group 1 ('+REDO1','+REDO2') size <size>;
