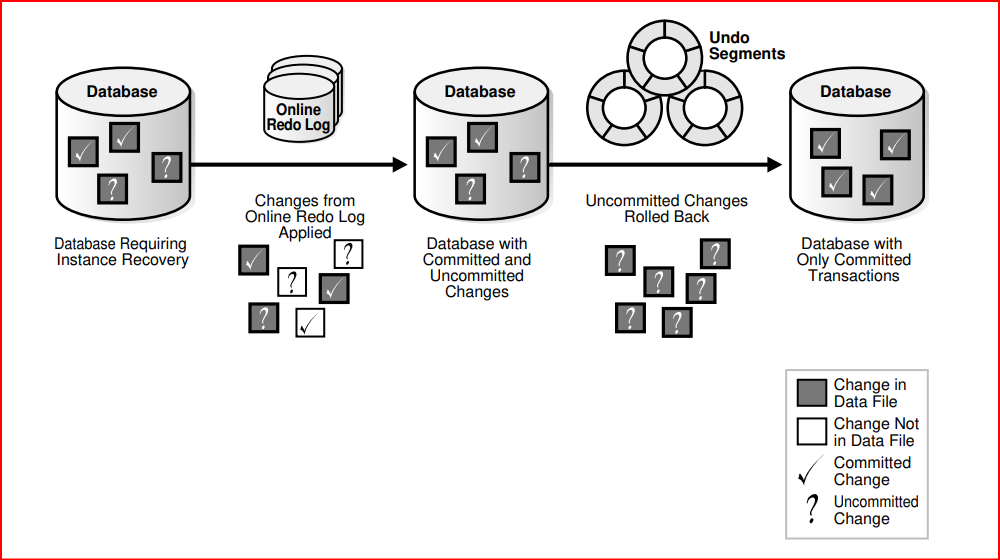
Instance recovery is the process of applying records in the online redo log to data files to reconstruct changes made after the most recent checkpoint.
Instance recovery occurs automatically when an administrator attempts to open a database that was previously shut down inconsistently.
Purpose of Instance Recovery
Instance recovery ensures that the database is in a consistent state after an instance failure. The files of a database can be left in an inconsistent state because of how Oracle Database manages database changes.
A redo thread is a record of all of the changes generated by an instance. A single instance database has one thread of redo, whereas an Oracle RAC database has multiple redo threads, one for each database instance.
When a transaction is committed, log writer process (LGWR) writes both the remaining redo entries in memory and the transaction SCN to the online redo log. However, the database writer (DBW) process writes modified data blocks to the data files whenever it is most efficient. For this reason, uncommitted changes may temporarily exist in the data files while committed changes do not yet exist in the data files.
If an instance of an open database fails, either because of a SHUTDOWN ABORT statement or abnormal termination, then the following situations can result: • Data blocks committed by a transaction are not written to the data files and appear only in the online redo log. These changes must be reapplied to the data files. • The data files contains changes that had not been committed when the instance failed. These changes must be rolled back to ensure transactional consistency. Instance recovery uses only online redo log files and current online data files to synchronize the data files and ensure that they are consistent.
When Oracle Database Performs Instance Recovery
Whether instance recovery is required depends on the state of the redo threads.
A redo thread is marked open in the control file when a database instance opens in read/write mode, and is marked closed when the instance is shut down consistently. If redo threads are marked open in the control file, but no live instances hold the thread enqueues corresponding to these threads, then the database requires instance recovery.
Oracle Database performs instance recovery automatically in the following situations:
• The database opens for the first time after the failure of a single-instance database or all instances of an Oracle RAC database. This form of instance recovery is also called crash recovery. Oracle Database recovers the online redo threads of the terminated instances together.
• Some but not all instances of an Oracle RAC database fail. Instance recovery is performed automatically by a surviving instance in the configuration. The SMON background process performs instance recovery, applying online redo automatically. No user intervention is required.
Importance of Checkpoints for Instance Recovery
Instance recovery uses checkpoints to determine which changes must be applied to the data files. The checkpoint position guarantees that every committed change with an SCN lower than the checkpoint SCN is saved to the data files.
The following figure depicts the redo thread in the online redo log.
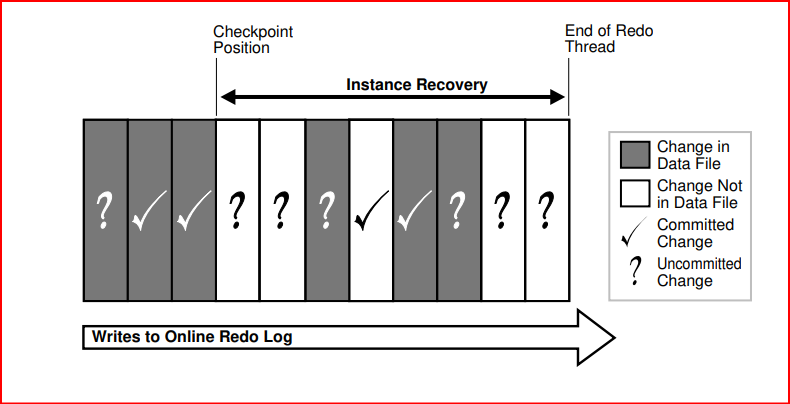
During instance recovery, the database must apply the changes that occur between the checkpoint position and the end of the redo thread. As shown in Figure , some changes may already have been written to the data files. However, only changes with SCNs lower than the checkpoint position are guaranteed to be on disk.
Instance Recovery Phases
The first phase of instance recovery is called cache recovery or rolling forward, and reapplies all changes recorded in the online redo log to the data files.
Because the online redo log contains undo data, rolling forward also regenerates the corresponding undo segments. Rolling forward proceeds through as many online redo log files as necessary to bring the database forward in time. After rolling forward, the data blocks contain all committed changes recorded in the online redo log files. These files could also contain uncommitted changes that were either saved to the data files before the failure, or were recorded in the online redo log and introduced during cache recovery.
After the roll forward, any changes that were not committed must be undone. Oracle Database uses the checkpoint position, which guarantees that every committed change with an SCN lower than the checkpoint SCN is saved on disk. Oracle Database applies undo blocks to roll back uncommitted changes in data blocks that were written before the failure or introduced during cache recovery. This phase is called rolling back or transaction recovery.